fabric的存储
在Hyperledger Fabric中有两个“存储”数据的地方:
>分类帐 >状态数据库
分类帐是实际的“区块链”.它是一个基于文件的分类帐,用于存储序列化块.每个块都有一个或多个事务.每个事务都包含一个读写集,用于修改一个或多个键/值对.分类帐是权威的最终来源,并且是不可变的.
状态数据库保存任何给定键的最后一个已知提交值.当每个对等方验证并提交事务时,它将被填充.始终可以通过重新处理分类帐来重建状态数据库.目前有两种状态数据库选项:嵌入式LevelDB或外部CouchDB.
另外,如果您熟悉Hyperledger Fabric通道,每个通道也有一个单独的分类帐.
在 Hyperledger Fabric 所提供 API 的帮助下,向区块链中加入一笔交易要经过如下步骤:
一笔交易预提案被提交后,由背书节点( endorsing peer )通过智能合约语言 chaincode 执行它的逻辑,同时它会查询状态数据库并生成要使用到的读写集( REset ),之后它还会连同生成的读写集返回交易预提案的回应。接下来,系统会将带有读写集的交易预提案提交。订购服务会把一批次的交易加入到区块中。所有的节点都会收到订购服务发来的区块信息,但它们需要验证区块中的交易信息来保证区块链中数据的安全性,步骤如下:
验证背书节点的执行策略;验证当前状态数据库中读写集的版本;向区块链中提交区块信息;向状态数据库中提交已验证过的交易信息。
1.账本存储概述
- peer节点账本存储图如下
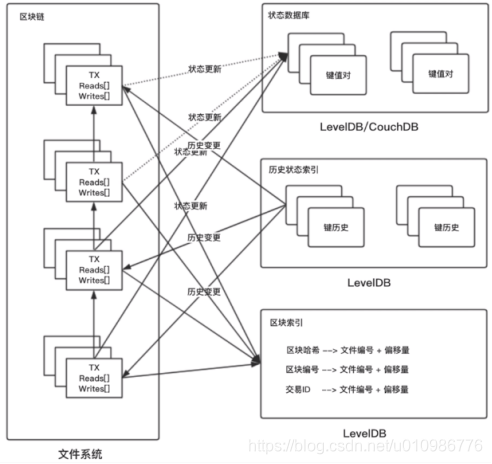
- 左边区块链是狭义上的区块存储,底层是一个文件系统,区块并不是存储在数据库,而是直接存储为文件
- 右下角的区块索引用于查询区块,将区块属性与区块位置关联,例如根据区块哈希、高度、交易ID查询区块
- 区块索引的实现使用了levelDB,是一个内嵌的数据库
- fabric中不是一个区块单独存一个文件,所以需要区块索引去查找
- 右上角状态数据库是区块链上的最新数据
2.交易读写集
- 交易读写集(RWSet)有三个概念
- 读集
- 写集
- 版本号
- 交易验证阶段需要对交易读写集进行验证
- 交易模拟&验证过程例子,现在假设有T1,T2,T3,T4和T5共5笔交易,所有模拟基于同一个世界状态
- 世界状态:(k1,1,v1)(k2,1,v2)(k3,1,v3)(k4,1,v4)——key,version和value
- T1通过验证,因为它并没有任何读操作,并且世界状态中k1和k2键的值分别更新为(k1,2,v1’)和(k2,2,v2’)
- T2不能通过验证,因为它读取了k1键的值,该值在T1中被修改了
- T3通过验证,因为它并没有任何读操作。并且世界状态中k2的值被更新为(k2,3,v2”)
- T4不能通过验证,因为它读取了k2键的值,该值在T1中被修改了
- T5通过验证,虽然读取了k5的值,但是k5的值之前交易并未修改过
3.账本存储其他概念
- 世界状态
- 交易执行后所有键的最新值
- 可以显著提升链码执行效率
- 历史数据索引
- 启用与否取决于智能合约是否有查询历史的需求
- 记录某个键在某区块的某条交易中被改变,只记录改变动作,不记录具体改变为了什么
- 区块存储
- 区块在fabric中以文件块存储,文件名是blocfile_xxxxxx(加一个6位数的编号)
- 现阶段,每个文件块大小是64M,需要更改的话,需要修改peer源码重新编译
- 区块读取
- 区块文件流
- 区块流
- 区块迭代器
- 区块索引
- 快速定位区块
- 索引键:区块高度、区块哈希、交易哈希
- 区块提交
- 保存区块文件
- 更新数据状态
4.账本存储源码
- 看core/ledger下的ledger_interface.go
- 读写集分为交易读写集生成和交易读写集验证两个部分
- 状态数据库
- core/ledger/kvledger/txmgmt/statedb/stateleveldb/stateleveldb.go
- 历史数据库
- core/ledger/kvledger/history/historydb/historyleveldb/historyleveldb.go
- 区块文件读取
- common/ledger/blkstorage/fsblkstorage/ fs_blockstore.go
5.账本存储总结
- 账本存储的接口定义,从总体上把握
- 交易读写集校验,防止双花攻击,比特币是用最长链来防止的
- 状态数据库及历史状态数据库
- 区块文件存储及区块索引
HLF 的存储系统和比特币一样,也是由普通的文件和 kv 的数据库(levelDB/couchDB)组成。在 HLF 中,每个 channel 对应一个账本目录,在账本目录中由 blockfile_000000、blockfile_000001 命名格式的文件名组成。为了快速检索区块数据每个文件的大小是64 M Bytes。每个区块的数据(区块头和区块里的所有交易)都会序列成字节码的形式写入 blockfile 文件中。
以下是区块数据写入的具体描述:
-
写入区块头数据,依次写入的数据为区块高度、交易哈希和前一个区块哈希;
-
写入交易数据,依次写入的数据为区块包含交易总量和每笔交易详细数据;
-
写入区块的 Metadata 数据,依次写入的数据为 Metadata 数据总量和每个 Metadata 项的数据详细信息。
在写入数据的过程中会以 kv 的形式保存区块和交易在 blockfile 文件中的索引信息,以方便 HLF 的快速查询。
HLF 区块索引信息格式在 kv 数据库中存储的最终的 LevelKey 值有前缀标志和区块 hash 组成,而 LevelValue 的值由区块高度,区块 hash,本地文件信息(文件名,文件偏移等信息),每个交易在文件中的偏移列表和区块的 MetaData 组成, HLF 按照特定的编码方式将上述的信息拼接成 db 数据库中的 value 。
HLF 交易索引信息格式在 kv 数据库中存储最终的 LevelKey 值由channel_name,chaincode_name 和 chaincode 中的 key 值组合而成:
LevelKey = channel_name + []byte{0x00} + chaincode_name + []byte{0x00} + key
而 LevelValue 的值由BlockNum 区块号,TxNum 交易在区块中的编号组成, HLF 通过将区块号和交易编号按照特定的方式编码,然后与 chaincode 中的 value 相互拼接最终生成 db 数据库中的 value 。
|  |